密码学课程作业:基于Java实现国产密码算法中的哈希算法SM3
Tips:本项目只做学习之用,未经全面测试和验证,不能用于实际项目中。
运行方法
- 下载代码:SM3.java(鼠标右键另存为),或者使用wget下载:
wget https://www.maoyingdong.com/files/SM3.java 在SM3.java目录下打开命令行窗口,编译并运行:
javac SM3.java java SM3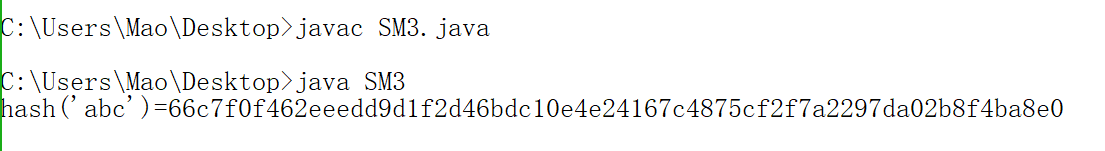
正常情况下会输出:hash('abc')=66c7f0f462eeedd9d1f2d46bdc10e4e24167c4875cf2f7a2297da02b8f4ba8e0。
SM3算法介绍
SM3是国家密码管理局编制的商用算法,它是一种杂凑算法,可以应用于数字签名、验证等密码应用中。其计算方法、计算步骤和运算实例可以在国家商用密码管理办公室官网查看。
该算法的输入是一个长度 L 比特的消息m,其中 L < 2^64 ,经过填充、迭代压缩后,生成一个256比特的输出。
算法步骤
填充长度
假设消息m 的长度为 L 比特。首先将比特“1”添加到消息的末尾,再添加k 个“0”, k是满足L + 1 + k ≡ 448 mod 512 的最小的非负整数。然后再添加一个64位比特串,该比特串是长度L的二进制表示。填充后的消息m′的比特长度为512的倍数。
在具体的实现过程中,首先获取消息超过512比特整数倍部分的长度L。由于在最后一个分组分组中,要将1个比特位“1”添加到消息的末尾,并且要添加64比特来存储消息的长度。
当 L <= 512-(64+1)时,可以直接填充比特位“1”、 512-(64+1)个比特位“0”、64位的消息长度,;当 L > 512-(64+1)时,最后一个512比特的分组不够填充,需要再添加一个512位的分组,此时填充的“0”的个数为k=512-L-1+(512-64)。
迭代压缩
在迭代的过程中,首先对填充后的消息m′按512比特进行分组。然后对每一个分组进行迭代压缩。迭代方式如下:
FOR i=0 TO n-1
V (i+1) = CF (V (i) , B (i) )
ENDFOR
上述算法中,n是填充后消息分组的个数,即有多少个消息分组,就迭代多少次。Vi是256位的向量,V0为初始值IV,即前一个分组计算完后的结果Vi会当作下一个分组的参数传入CF函数中,此即是密码学中扩散原则,即原始消息的任意比特位的变化都会造成结果产生大的改变。
在CF压缩函数中,需要用到的参数有向量V (i)、B(i)、常量Tj、Wj和Wj′。其中Wj和Wj′是对512比特的消息分组进行扩展后产生的132个字。由于消息分组有多个,Wj和Wj′也对应有多个。在具体实现时,要在CF函数中对每一个消息分组进行消息扩展计算。
在迭代完最后一个消息分组后,CF函数返回的值Vn就是最终的计算结果。
实现过程
创建项目
打开Eclipse创建项目SM3,在项目SM3中创建类SM3。创建完成后目录结构如下所示:
定义算法中的常量、函数
算法中需要用到函数FFj、GGj、P0、P1、常量Tj等,以及原始消息、填充后的消息定义如下:
// 字符集
private String charset = "ISO-8859-1";
// 要哈希的字符串
private String message = "abc";
// 填充后的字符串
private String PaddingMessage;
// 获取常量T0和T1
private int T(int j){
if(j <= 15){
return 0x79cc4519;
}else{
return 0x7a879d8a;
}
}
// 布尔函数 FF
private int FF(int X, int Y, int Z, int j)
{
int result = 0;
if(j >= 0 &&j <= 15)
{
result = X ^ Y ^ Z;
}else if(j >= 16 && j <= 63)
{
result = (X & Y) | (X & Z) | (Y & Z);
}
return result;
}
// 布尔函数GG
private int GG(int X, int Y, int Z, int j)
{
int result = 0;
if(j >= 0 &&j <= 15)
{
result = X ^ Y ^ Z;
}else
{
result = (X & Y) | (~X & Z);
}
return result;
}
// 置换函数P0
private int P0(int X)
{
return X ^ (CircleLeftShift(X, 9)) ^ CircleLeftShift(X, 17);
}
// 置换函数P1
private int P1(int X)
{
return X ^ (CircleLeftShift(X, 15)) ^ CircleLeftShift(X, 23);
}
在上述函数定义中,用到的CircleLeftShift函数用于实现循环左移,它的两个参数分别是要移位的32位int型数据和循环左移的位数。在循环左移中,循环左移k位,相当于将二进制位最左边的k位移动到最右边。
调试方法编写
在课本的运算示例中,每一步运算的中间结果都有。在编写算法时,每写一步都要与课本上的中间结果对照,以确定当前得到的中间结果是否正确。由于算法运行的中间结果都是二进制形式,为方便查看,编写了dump方法用于将中间结果显示为16进制的形式。如将填充后的消息打印出来的dump方法如下:
private void dump()
{
System.out.println("========开始打印========");
try{
byte bts[] = this.PaddingMessage.getBytes(this.charset);
for(int i = 0; i < bts.length; i ++)
{
if(i%16 != 0 && i%2 == 0 && i != 0){
System.out.print(" ");
}
if(i%16 == 0 && i != 0){
System.out.println();
}
System.out.printf("%02x", bts[i]);
}
}catch(Exception e){
System.out.println("Error Catch");
}
System.out.println("\n========结束打印========");
}
在输入消息为“abc”的情况下,打印填充后的消息的十六进制形式如下所示:

其中开头的61、62、63是字母a、b、c对应的ASCII码,80是填充消息时附加的比特位1,该比特位与后面填充的比特位0,构成了二进制1000 0000,所以对应的十六进制是80。最后的18也是十六进制形式,对应的十进制是24,表示消息的长度是24位。
由于在使用Java编写SM3算法时,计算的中间结果有字符串、整型数组等多种类型,为方便查看对应数据的十六进制形式,编写了多个dump方法,用于打印各种类型的数据。
/* 将字符串输出为16进制形式 */
private static void dump(String str)
/* 将整型数组输出为16进制形式 */
private static void dump(int nums[])
遇到的错误及解决方案
循环左移计算结果偶尔不正确
在Java中,只有按位左移<<操作符,按位左移溢出的比特位直接丢弃,而SM3算法需要的循环左移需要将溢出的比特位存储到操作数最右边。
在实现循环左移时,假设要移位的32位比特位的数据为Y,则循环左移位可以分为三步:
①把Y按位左移k位的值赋值为l,此时l最右边的k位为0;
②把Y按位右移(32-k)位的值赋值为r,此时r左边的(32-k)位为0;
③将l和r进行按位或运算,即得到循环左移后的结果。
例如将0x1234 5678按位左移8位,则Y左移8位得到 l=0x3456 7800,Y右移32-8=24位得到r=0x0000 0012,最后将l和r进行按位或运算得到最终结果0x34567812。
循环左移的实现过程如下:
// 将x循环左移N位
private static int CircleLeftShift(int x, int N)
{
return (x << N) | (x >> (32 - N));
}
在使用此方法进行按位左移时,发现偶尔计算出来的结果与预期不符合。经过调试,发现是在按位右移时没有得到预期的结果,导致最终循环左移结果出错。具体原因及分析如下:
按位左移是直接在右边补0,而按位右移分为两种情况,一种是逻辑右移(有符号移位),一种是算术右移(无符号移位)。
逻辑右移是当最高位为0是,说明这是一个正数,右移时在最左边补0;当最高位为1时,说明这是一个负数,负数在计算机中以补码形式存储,所以逻辑右移时在最左边补1。
而算术左移在移位时忽略符号位,即无论最高位是0还是1,都往最左边补0。
在SM3算法中,需要的是算术右移。而在Java的语法中,>>是逻辑右移,>>>是算术右移。最初使用逻辑右移,导致循环左移最高位为1的数时运算结果与期望值不符。
修改后的循环左移方法如下:
// 将x循环左移N位
private static int CircleLeftShift(int x, int N)
{
return (x << N) | (x >>> (32 - N));
}
填充消息时附加比特位1结果不对
根据算法的计算步骤,填充消息时,首先在消息后面附上一个比特位1。在实现算法时,由于用户输入的都是以字节为单位的字符串,所以1之后填充的0的个数k肯定是符合7+8*Z的,其中Z为非负整数。所以可以附加一个比特位“1”的操作可以转化为附加二进制1000 0000。实现代码如下:
padding += (byte)0x80; // 先填充一个“1000 0000”
其中padding是一个字符串类型的数据,用于存储附加的数据。填充完比特位1、k个0以及消息长度后,将填充后的消息打印出来,如下:
测试时输入的消息依旧是abc,理论上得到的是6162 6380 0000 0000 .....,将消息c即63后的十六进制位2d 3132 38与ASCII表对照,发现是-128。原因很明确,byte类型的0x80表示的数正是-128。而将-128与字符串padding进行 +=操作时,byte类型的数据被转换成字符串-128,所以得到上图的结果。
既然不能直接将byte类型的数据与字符串相连接,那可以尝试使用new String(byte[] bytes[])方法将一个byte数组转换成字符串。修改代码如下:
byte a[] = { (byte) 0x80 };
padding += new String(a); // 先填充一个“1000 0000”
再次运行后结果还是不正确,如下图所示:
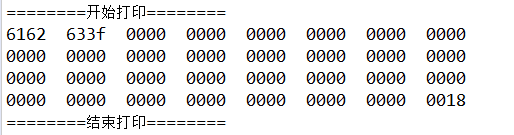
结果显示原本的0x80变成了0x3f。经过测试发现,0x01最后会得到0x01,0x02会得到0x02,0x7f也会得到0x7f,只有当大于0x7f是结果才会不正确,而且得到的都是0x3f。
在网上搜索之后,得出错误的原因:ASCII是每个字节对应一个字符,一个字节的表示范围是-128~127,而ASCII只对0~127这个范围进行了编码。也就是每个字节最大值是0x7f,用二进制表示就是最高位为0。上面的0x80的二进制位是1000 0000,最高位是1,不在ASCII编码的范围之内。Java使用的是Unicode字符集,当进行将0x80转换成字符时,Java在Unicode代码页中查询不到对应的字符,Java会默认返回一个0x3f。所以上面试验中,小于0x80的byte可以正确转换成字符串,而大于等于0x80的byte数据将会返回0x3f.
解决方法是将byte数组转化成字符串时设置编码为“ISO-8859-1”。ISO-8859-1是按字节编码的,并且它对0~255的空间都进行了编码,所在在转换时它能够正确的将0x80转换为字符串。实现代码如下:
byte a[] = {(byte)0x80};
padding += new String(a, charset);
其中第二个参数charset是在最前面定义的字符集,它是一个字符串“ISO-8859-1”。再次运行并打印填充后的消息,发现结果跟预期一致:
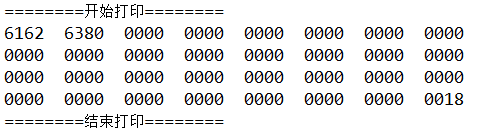
迭代时结果出错
在进行迭代的时候,导出了迭代前的数据,包括Wj,Wj′等,都与课本上的示例一样。说明迭代前的步骤已经正确的完成。迭代后的结果却不正确,说明错误出现在迭代这里。将中间结果ABCDEFGH导出后与课本上的对照,发现最开始出错的位置是G0,而G0之前的A-F都是正确的。
课本上的:
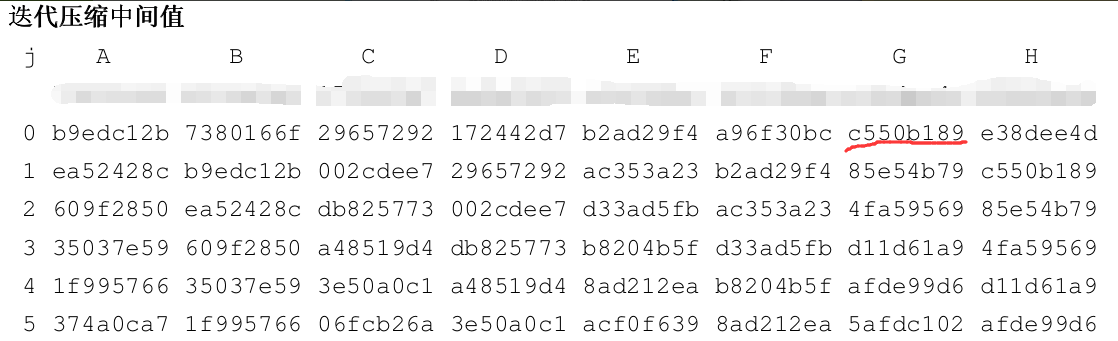
实验中的:

查看课本上的算法G赋值的位置,算法如下:
G ← F <<< 9
此时怀疑移位算法是否编写正确,经过手算移位算法后,发现结果和实验中的显示的一样。对照国家密码管理局发布《SM3密码杂凑算法》发现,课本上的算法不对,正确的移位数应该是19,即:
G ← F <<< 19
修改为正确的移位数后再次运行,发现结果与课本上的一致,SM3密码算法完成。哈希结果如下:
66c7f0f462eeedd9d1f2d46bdc10e4e24167c4875cf2f7a2297da02b8f4ba8e0
源代码
完整源代码下载地址: Github